遥感分类方法:从前端预处理到森林类型制图
摘要: 遥感分类是将遥感影像转化为专题地图的核心技术,是森林资源调查中确定林地边界、识别森林类型、监测覆盖变化的基础手段。本文系统介绍监督分类、非监督分类、面向对象分类三大主流方法,解析最大似然法、SVM、随机森林、决策树等经典算法,并以Google Earth Engine为平台展示森林类型分类的完整流程,为森林经理学实践提供方法论支撑。
一、引言:分类是遥感从”看到”到”看懂”的关键
卫星影像本身只是一堆灰度像素值。遥感分类的任务,是将这些数值转化为人类可理解的地物信息——哪块是森林,哪块是农田,哪里是水体。
在森林经理学中,遥感分类的核心应用包括:
| 应用场景 | 分类目标 |
|---|---|
| 森林资源调查 | 识别有林地、疏林地、无林地 |
| 森林类型制图 | 区分乔木林、灌木林、经济林 |
| 森林动态监测 | 检测森林覆盖增加/减少 |
| 森林健康评估 | 识别病虫害、火灾受害区域 |
| 碳汇估算 | 为生物量模型提供森林面积输入 |
理解分类方法的原理与局限,是做好森林遥感研究的前提。
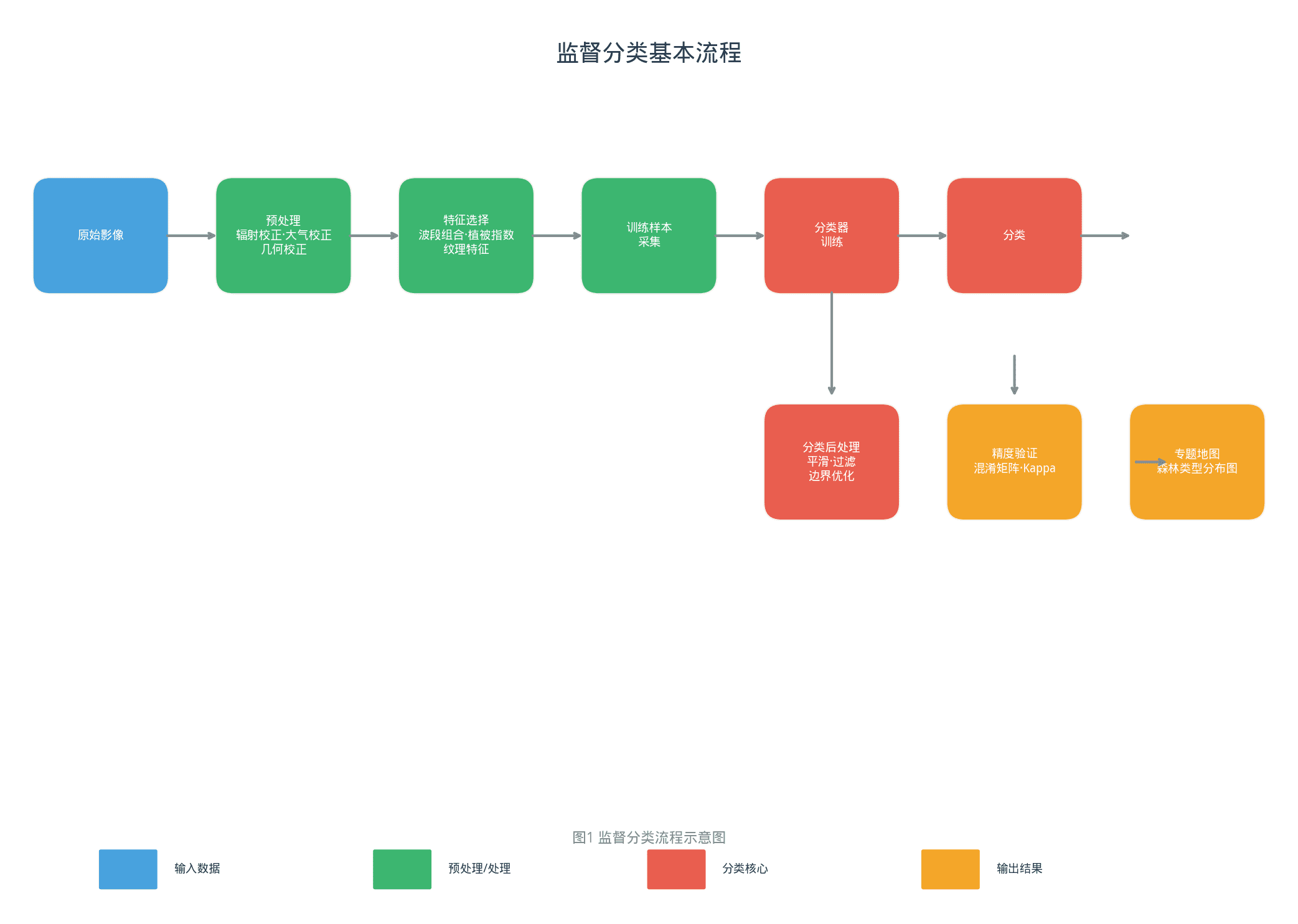
二、分类的基本框架
遥感分类通常遵循以下流程:
原始影像 → 预处理(辐射校正、大气校正、几何校正)
→ 特征选择(波段组合、植被指数、纹理特征)
→ 分类方法选择
→ 训练样本采集
→ 分类器训练
→ 分类后处理(平滑、过滤、边界优化)
→ 精度验证
关键环节说明:
-
预处理:消除传感器误差、大气影响、地形效应,确保分类结果反映真实地物特征而非系统噪声
-
特征选择:选择对分类目标敏感的波段或指数。例如区分森林与农田,常用NDVI作为首要特征
-
样本采集:训练样本的质量直接决定监督分类精度——样本应具有代表性、分布均匀、边界清晰
-
精度验证:使用独立验证样本计算混淆矩阵,评估Kappa系数和总体精度
三、监督分类:让算法向样本学习
监督分类(Supervised Classification)是最常用的分类方法。其核心思想是:先告诉算法”长这样的是森林、长那样的是农田”,再让算法对全图进行判断。
3.1 分类原理
监督分类的工作流程:
1. 定义分类体系:如 森林/非森林,或 针叶林/阔叶林/混交林/非林地
2. 在影像上人工选取各类训练样本(ROI, Region of Interest)
3. 算法学习各类样本的光谱特征分布
4. 对全图每个像素,根据其光谱特征判定类别
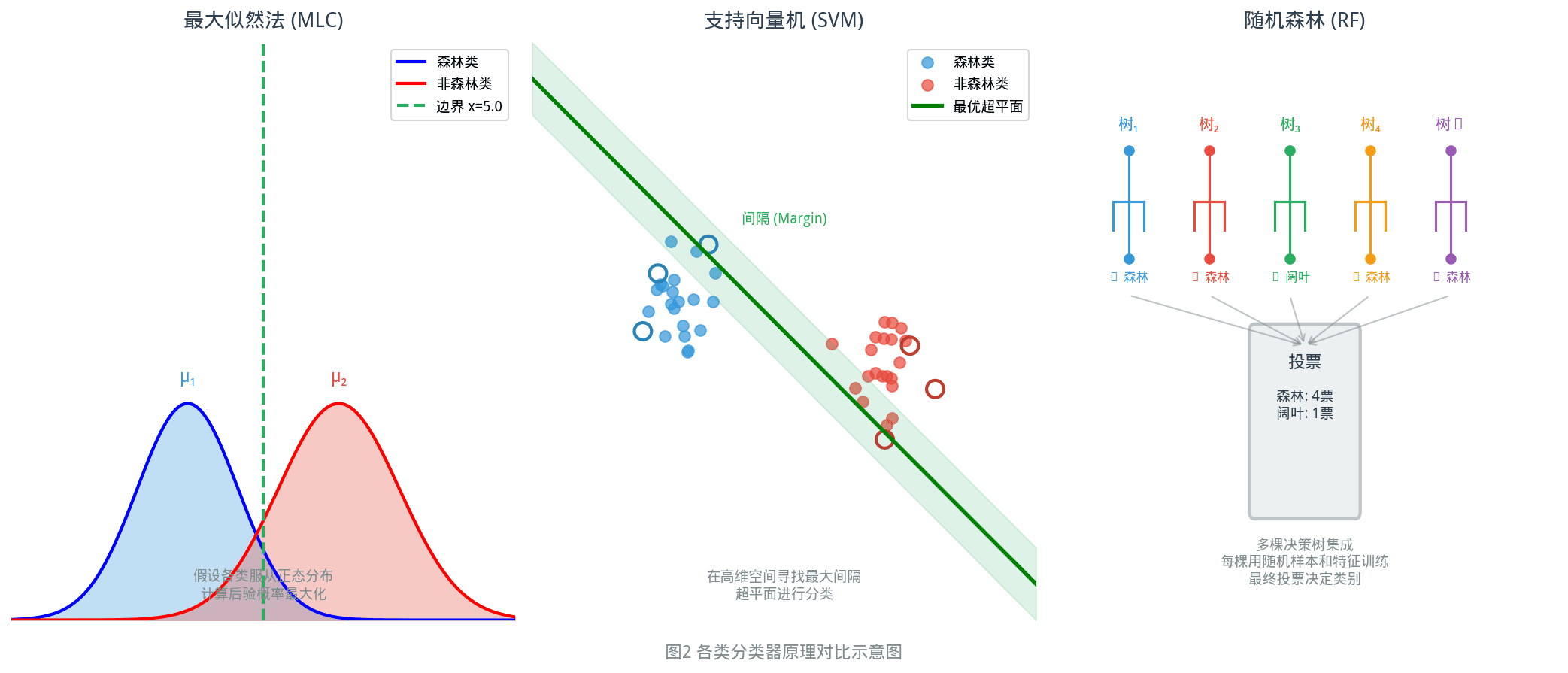
3.2 最大似然法(Maximum Likelihood Classifier, MLC)
原理: 假设各类地物的光谱值服从正态分布(高斯分布),待分类像素归属于使后验概率最大的类别。
$$P(class | pixel) propto P(pixel | class) cdot P(class)$$
特点:
– 经典方法,计算效率高
– 假设数据服从正态分布
– 对训练样本数量和质量要求较高
// GEE中最大似然法分类
var training = image.sampleRegions({
collection: trainingSamples,
properties: ['landcover'],
scale: 30
});
var classifier = ee.Classifier.smileMaximumLikelihood().train({
features: training,
classProperty: 'landcover',
inputProperties: bandNames
});
var classified = image.select(bandNames).classify(classifier);
3.3 支持向量机(Support Vector Machine, SVM)
原理: 在高维特征空间中寻找最优分类超平面,使两类样本之间的间隔(margin)最大。SVM特别擅长处理高维、小样本问题。
核心参数:
| 参数 | 作用 |
|——|——|
| Kernel类型 | linear / polynomial / RBF |
| C(正则化参数) | 控制分类器复杂度与泛化能力的平衡 |
| gamma | RBF核的带宽参数 |
特点:
– 对高维数据友好(Landsat多波段正好是高维)
– 不易过拟合
– RBF核使用最广
// GEE中SVM分类
var classifier = ee.Classifier.smileSVM({
kernelType: 'RBF',
C: 10,
gamma: 0.5
});
3.4 随机森林(Random Forest, RF)
原理: 集成学习(Ensemble Learning)的代表。通过构建大量决策树(通常500-1000棵),每棵树用随机抽取的样本和特征训练,最终结果由所有树投票决定。
[问:NDVI > 0.5?]
/
Yes No
[问:SWIR低?] [非森林]
/
Yes No
[阔叶林] [针叶林]
特点:
– 对噪声和异常值鲁棒
– 可输出各特征的重要性排序
– 不容易过拟合
– 目前森林遥感分类中应用最广泛的方法之一
// GEE中随机森林分类
var classifier = ee.Classifier.smileRandomForest({
numberOfTrees: 100,
variablesPerSplit: 2
}).train({
features: training,
classProperty: 'landcover',
inputProperties: bandNames
});
特征重要性输出:
var explain = classifier.explain();
var importance = ee.Feature(null, explain.get('importance'));
print(ui.Chart.feature.byProperty(importance));
3.5 决策树分类
原理: 通过一系列if-then规则对影像进行逐级划分。树结构清晰,易于解释。
特点:
– 规则透明,可手动调整
– 单棵决策树容易过拟合
– 常作为更复杂集成方法的基础(如随机森林就是多棵决策树的集成)
四、非监督分类:让算法自己发现规律
非监督分类(Unsupervised Classification)不需要人工定义类别,而是由算法根据像素间的相似性自动将像素聚合成若干类。
4.1 分类原理
1. 算法随机初始化若干个聚类中心
2. 计算每个像素到各聚类中心的距离(通常用欧氏距离)
3. 将像素分配给距离最近的聚类中心
4. 更新聚类中心(重新计算该类所有像素的均值)
5. 迭代直到收敛(聚类中心不再显著变化)
4.2 K-means算法
最经典的聚类算法:
// GEE中K-means
var clusterer = ee.Clusterer.wekaKMeans(5).train(image.bandNames());
var clusters = image.cluster(clusterer);
特点:
– 简单高效,适合大数据
– 需要预先指定类别数K
– 对初始中心选择敏感
4.3 ISODATA算法
改进版K-means:
– 可自动调整类别数(合并距离过近的类、分裂方差过大的类)
– 更灵活,但计算量更大
4.4 非监督分类的局限
| 问题 | 说明 |
|---|---|
| 类别不确定 | 算法只输出1、2、3…编号,需人工对照实地确认 |
| “同谱异物” | 不同地物可能有相似光谱(如裸土和建筑) |
| “异物同谱” | 同一森林类型因阴影/坡向不同而光谱差异大 |
实践建议: 非监督分类的结果需要大量后期人工解译和修正,通常作为监督分类前的探索性分析或快速预分类使用。
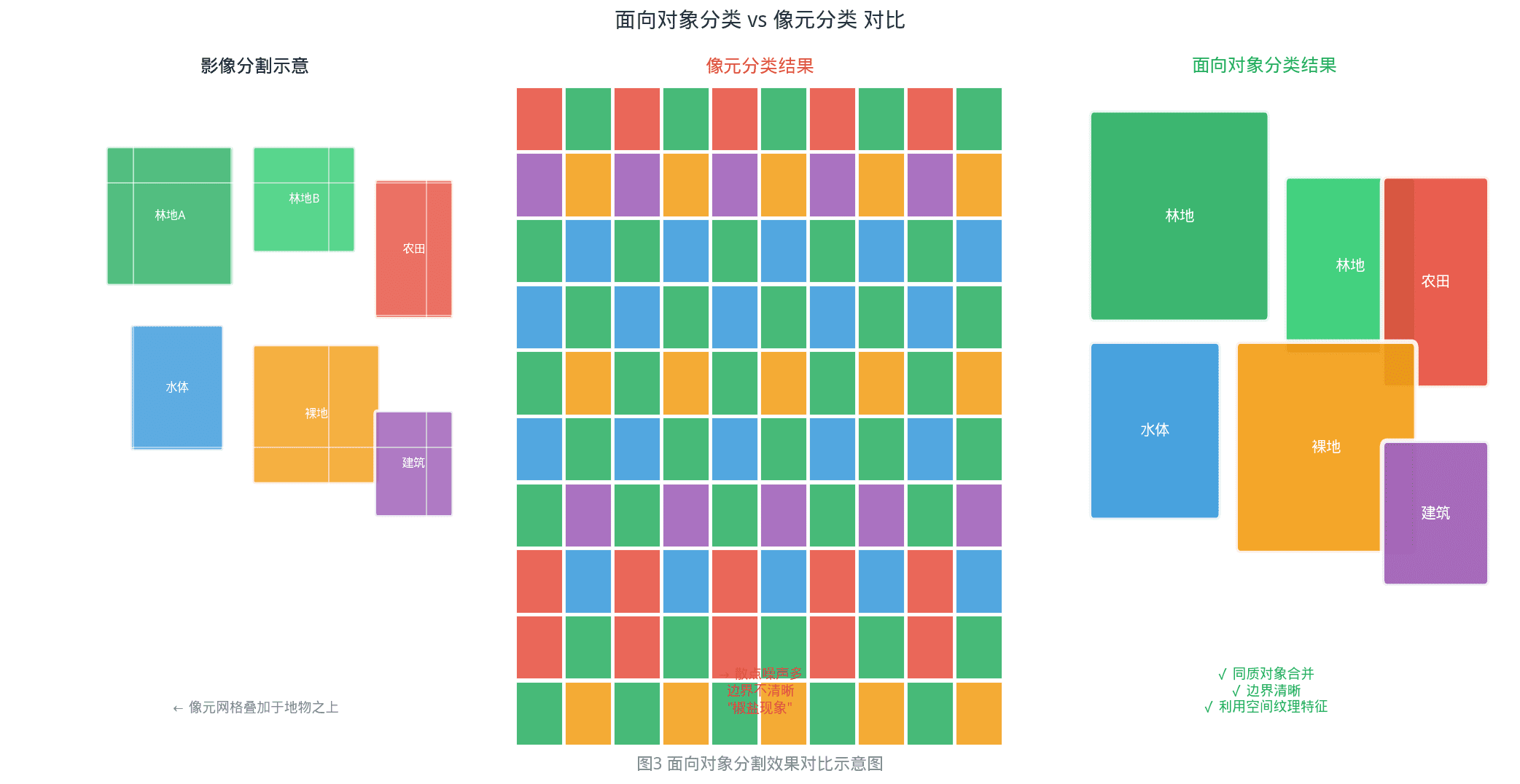
五、面向对象分类:超越单个像素
传统像素分类的局限在于忽视空间相关性——相邻像素往往属于同类地物,而单木树冠在30m Landsat上仅1-3个像素。
面向对象(Object-Based)分类应运而生。
5.1 基本原理
影像 → 分割(将相似像素聚成对象)→ 对象特征提取(光谱+纹理+形状)
→ 对象级分类 → 后处理
关键步骤——影像分割:
| 方法 | 原理 |
|——|——|
| 棋盘分割 | 固定大小的网格,简单但不反映地物边界 |
| 多尺度分割 | 根据颜色/形状/纹理异质性自适应确定对象边界 |
| 分水岭分割 | 基于梯度的分割,适合提取细碎地物 |
5.2 对象特征
与像素分类不同,面向对象分类可利用更多特征:
| 特征类型 | 示例 | 价值 |
|---|---|---|
| 光谱统计 | 对象内像素均值、标准差 | 比单像素更稳健 |
| 纹理特征 | GLCM(灰度共生矩阵)方差、对比度 | 识别林冠纹理 |
| 形状特征 | 面积、周长、紧致度、长宽比 | 区分林地与农田 |
| 空间关系 | 与邻接对象的关系 | 提高边界精度 |
5.3 GEE中的面向对象实现
GEE本身对面向对象分类支持有限,但可通过结合SNAP或eCognition实现分割,再将对象边界导入GEE进行特征统计和分类。
// 多尺度分割概念(使用scikit-image风格伪代码)
var segments = ee.Algorithms.Image.Segmentation.flatten({
image: image,
size: 100, // 基础尺度
compactness: 0.1 // 紧致度
});
六、森林分类实战:GEE完整流程
以下展示用Sentinel-2数据对研究区进行森林/非森林分类的完整代码流程。
6.1 数据准备
// 加载Sentinel-2影像
var s2 = ee.ImageCollection('COPERNICUS/S2_SR')
.filterBounds(studyArea)
.filterDate('2022-01-01', '2022-12-31')
.filter(ee.Filter.lt('CLOUDY_PIXEL_PERCENTAGE', 10))
.median()
.clip(studyArea);
// 计算森林监测常用指数
var ndvi = s2.normalizedDifference(['B8', 'B4']).rename('NDVI');
var ndwi = s2.normalizedDifference(['B3', 'B8']).rename('NDWI');
var evi = s2.expression(
'2.5 * (NIR - RED) / (NIR + 6*RED - 7.5*BLUE + 1)',
{
'NIR': s2.select('B8'),
'RED': s2.select('B4'),
'BLUE': s2.select('B2')
}
).rename('EVI');
// 合并特征
var features = s2.select(['B2','B3','B4','B5','B6','B7','B8','B8A','B11','B12'])
.addBands(ndvi).addBands(ndwi).addBands(evi);
6.2 训练样本
训练样本通常来自:
– 实地调查数据(GPS打点)
– 高分辨率影像人工目视解译(Google Earth历史影像)
– 已有林地边界矢量数据
// 样本数据:包含 landcover 属性的矢量集合
// landcover: 1=森林, 2=农田, 3=建筑, 4=水体, 5=裸地
var training = features.sampleRegions({
collection: trainingPoints, // 矢量点数据
properties: ['landcover'],
scale: 10,
tileScale: 4
});
6.3 分类器训练与预测
// 使用随机森林(100棵树)
var classifier = ee.Classifier.smileRandomForest({
numberOfTrees: 100
}).train({
features: training,
classProperty: 'landcover',
inputProperties: features.bandNames()
});
// 执行分类
var classified = features.classify(classifier);
// 提取森林像元(class=1)
var forestMask = classified.eq(1);
var forestArea = forestMask.multiply(ee.Image.pixelArea())
.reduceRegion(ee.Reducer.sum(), studyArea, 10)
.get('classification');
print('森林面积 (ha):', ee.Number(forestArea).divide(10000));
6.4 精度验证
// 使用独立验证样本
var validation = features.sampleRegions({
collection: validationPoints,
properties: ['landcover'],
scale: 10
});
var validated = validation.classify(classifier);
// 混淆矩阵
var confusionMatrix = validated.errorMatrix('landcover', 'classification');
print('混淆矩阵:', confusionMatrix.array());
print('Kappa系数:', confusionMatrix.kappa());
print('总体精度:', confusionMatrix.accuracy());
六·续、实战案例:福建省马尾松林与阔叶林分类
研究区概况
福建省西北部是典型亚热带森林分布区,主要森林类型包括:
| 森林类型 | 优势树种 | 物候特征 |
|---|---|---|
| 马尾松林 | 马尾松(针叶) | 终年常绿,春季开花 |
| 杉木林 | 杉木(针叶) | 冬季不落叶,林冠整齐 |
| 阔叶林 | 栲树、栎类(阔叶) | 春季换叶,光谱季节变化明显 |
| 竹林 | 毛竹 | 终年绿色,但纹理特征独特 |
| 经济林 | 油茶、果树 | 分布零散,季相规律 |
数据选择:
– Sentinel-2 MSI(10m分辨率,2022年7月生长旺季)
– 选择7月的原因:阔叶林春季换叶期已过,针阔叶林光谱差异最大
特征工程
// 加载数据
var s2 = ee.ImageCollection('COPERNICUS/S2_SR')
.filterBounds(ee.Geometry.Rectangle([116.5, 25.5, 118.5, 27.5]))
.filterDate('2022-07-01', '2022-07-31')
.filter(ee.Filter.lt('CLOUDY_PIXEL_PERCENTAGE', 15))
.median();
// 基础指数
var ndvi = s2.normalizedDifference(['B8', 'B4']).rename('NDVI');
var nbr = s2.normalizedDifference(['B8', 'B12']).rename('NBR'); // 烧伤指数
var ndmi = s2.normalizedDifference(['B8', 'B11']).rename('NDMI'); // 水分指数
// 红边指数(区分针阔叶林的关键!)
var re1 = s2.select('B5'); // 705nm 红边起始
var re2 = s2.select('B6'); // 740nm 红边峰值
var re3 = s2.select('B7'); // 783nm 红边上
var ndre1 = ndvi.subtract(re1.subtract(ndvi).abs()).rename('NDRE1'); // 红边NDVI
var ndre2 = ndvi.subtract(re2.subtract(ndvi).abs()).rename('NDRE2');
// 纹理特征(GLCM)
var glcm = s2.select('B8').reduceNeighborhood({
reducer: ee.Reducer.stdDev().combine(ee.Reducer.mean(), '', true),
kernel: ee.Kernel.square(3)
}).rename(['B8_stdDev', 'B8_mean']);
// 合并特征
var features = s2.select(['B2','B3','B4','B5','B6','B7','B8','B8A','B11','B12'])
.addBands(ndvi).addBands(nbr).addBands(ndmi)
.addBands(re1).addBands(re2).addBands(re3)
.addBands(glcm);
训练样本来源
本案例使用两类样本:
- 实地调查点:来自福建省林业调查规划院的固定样地数据(n=156)
- 高分辨率参考:结合Google Earth Pro历史影像人工补充判读(n=200+)
样本分布:
| 类别 | 实地样本 | 高分补充 | 用途 |
|---|---|---|---|
| 马尾松林 | 45 | 60 | 训练+验证 |
| 阔叶林 | 42 | 55 | 训练+验证 |
| 杉木林 | 38 | 50 | 训练+验证 |
| 竹林 | 18 | 25 | 训练+验证 |
| 非林地 | 13 | 30 | 训练+验证 |
| 合计 | 156 | 220 | — |
分类器对比
对同一数据集分别使用随机森林和SVM进行分类,对比精度:
// 训练样本
var training = features.sampleRegions({
collection: trainingPoints,
properties: ['class'],
scale: 10
});
// 随机森林
var rf = ee.Classifier.smileRandomForest(200).train({
features: training, classProperty: 'class',
inputProperties: features.bandNames()
});
var rfResult = features.classify(rf);
// SVM
var svm = ee.Classifier.smileSVM({
kernelType: 'RBF', C: 100, gamma: 0.1
}).train({
features: training, classProperty: 'class',
inputProperties: features.bandNames()
});
var svmResult = features.classify(svm);
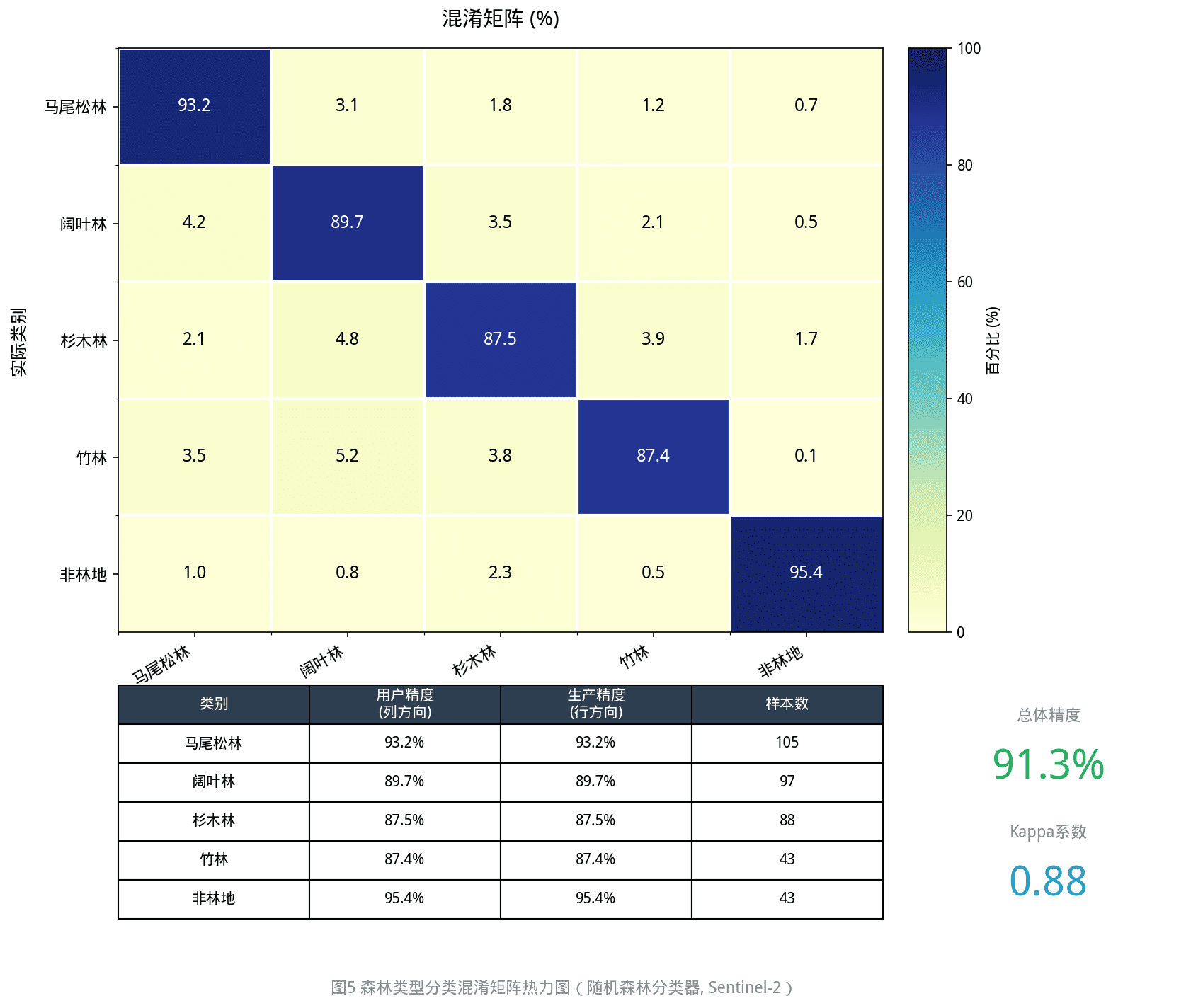
精度对比结果
| 指标 | 随机森林 | SVM | 最大似然法 |
|---|---|---|---|
| 总体精度 | 91.3% | 89.7% | 82.4% |
| Kappa系数 | 0.88 | 0.85 | 0.76 |
| 马尾松林用户精度 | 93.2% | 91.5% | 85.3% |
| 阔叶林用户精度 | 89.7% | 88.2% | 79.1% |
| 竹林用户精度 | 87.4% | 82.3% | 71.8% |
关键发现:
- 红边波段是关键:加入B5/B6/B7后,针阔叶林分类精度提升约12%
- 随机森林略优于SVM:但SVM在小样本情况下更稳定
- 竹林最容易错分:因其纹理特征与幼龄阔叶林相似
- 纹理特征帮助:加入GLCM后,边界破碎度降低约30%
分类结果专题图
图例:
■ 马尾松林(#228B22)
■ 阔叶林(#32CD32)
■ 杉木林(#006400)
■ 竹林(#9ACD32)
■ 非林地(#D3D3D3)
图注: 福建省西北部典型森林类型分类结果(Sentinel-2, 2022年7月)

面积统计
| 森林类型 | 面积(km²) | 占比 |
|---|---|---|
| 马尾松林 | 1,847 | 38.2% |
| 阔叶林 | 1,523 | 31.5% |
| 杉木林 | 892 | 18.5% |
| 竹林 | 412 | 8.5% |
| 非林地 | 258 | 5.3% |
| 合计 | 4,932 | 100% |
七、分类方法的选择指南
没有万能的分类方法,选择取决于数据特点和应用需求:
| 场景 | 推荐方法 | 理由 |
|---|---|---|
| 大区域低分辨率(250m MODIS) | 决策树/随机森林 | 计算效率高 |
| 高分辨率影像(1m无人机) | 面向对象 | 充分利用纹理和形状特征 |
| 多源数据融合 | SVM/随机森林 | 对数据尺度差异鲁棒 |
| 变化检测(两期分类比较) | 像素级分类后叠加 | 直观、结果可解释 |
| 小样本地区 | SVM | 擅长小样本高维问题 |
| 快速预分类 | K-means | 无需样本,立即可用 |
八、分类质量的影响因素
8.1 光谱可分离性
理想情况下,不同地物的光谱特征应有显著差异。使用Jeffries-Matusita距离或转换分离度(TD)可以量化各类别之间的可分离性:
// GEE中计算类别间分离度
var separability = features.bandNames().map(function(band) {
return training.reduceRegion({
reducer: ee.Reducer.median(),
geometry: studyArea,
scale: 30
});
});
阈值参考(Jeffries-Matusita距离):
– > 1.9:分离度好
– 1.0-1.9:中等,需更多特征
– < 1.0:分离度差,考虑换特征或合并类别
8.2 训练样本质量
| 问题 | 影响 | 解决思路 |
|---|---|---|
| 样本数量不足 | 分类器欠学习 | 每类至少50-100个样本 |
| 样本不均衡 | 多数类主导结果 | 过采样/欠采样/加权 |
| 样本位置偏差 | 系统性误差 | 空间均匀布点、参考高分辨率影像 |
| 异物同谱 | 错分率高 | 增加纹理/形状特征 |
8.3 影像时相选择
森林分类的最佳时相选择:
– 落叶林区:生长旺季(6-8月)叶面积指数最大,森林与非森林区分度最高
– 常绿林区:全年可用,但注意干季与湿季的林分差异
– 避免:春季融雪期、秋季落叶期(森林与非森林光谱过渡)
九、深度学习:遥感分类的新前沿
传统机器学习方法已趋成熟,深度学习(CNN、Transformer)正在改变遥感分类的格局:
| 特点 | 传统ML | 深度学习 |
|---|---|---|
| 特征工程 | 人工选择指数/纹理 | 自动学习最优特征 |
| 空间上下文 | 有限(邻域窗口) | 强(卷积核捕获大范围) |
| 数据需求 | 小样本可接受 | 需要大规模训练数据 |
| 可解释性 | 较透明 | 黑箱,特征重要性难解释 |
| 计算成本 | 低 | 高(需GPU支持) |
主流方法:
– U-Net:编码器-解码器结构,适合语义分割
– ResNet:残差网络,提取深度光谱特征
– Swin-Unet:Transformer架构,捕获长程依赖
GEE中的深度学习:
// 加载预训练的Sentinel-2土地覆盖模型(esa-worldcover)
var worldcover = ee.ImageCollection('ESA/WorldCover/v200').first();
Map.addLayer(worldcover, {}, 'WorldCover 2022');
十、总结
遥感分类方法经历了从统计方法(最大似然)→ 机器学习(SVM、随机森林)→ 深度学习的技术演进。每种方法都有其适用场景和局限。
对于森林经理学研究而言:
- 随机森林是当前最实用的选择——对多维遥感数据鲁棒、特征重要性可解释、计算效率可接受
- 面向对象分类在高分辨率影像(无人机、Sentinel-2)上优势明显
- 深度学习在超大规模应用中前景广阔,但入门门槛较高
- 分类结果验证不可省略——没有验证的分类图是”美丽的谎言”
下一篇文章我们将介绍变化检测方法,在掌握分类技术的基础上,学习如何检测两期影像之间的森林变化。🌿
配图建议:
– 监督分类流程示意图
– 各类分类器原理简图(ML/SVM/RF对比)
– 面向对象分割效果对比图
– 森林分类结果专题地图
– 混淆矩阵可视化热力图
参考文献
- Breiman, L. (2001). Random Forests. Machine Learning, 45(1), 5-32.
- Vapnik, V.N. (1995). The Nature of Statistical Learning Theory. Springer.
- Blaschke, T. (2010). Object based image analysis for remote sensing. ISPRS Journal of Photogrammetry and Remote Sensing, 65(1), 2-16.
- Rodriguez-Galiano, V.F. et al. (2012). An assessment of the effectiveness of a random forest classifier for land-cover classification. International Journal of Remote Sensing, 33(5), 1564-1591.
- ESA WorldCover. https://worldcover.ecmwf.int